作者简介:大厂一线资深开发。从crud开发到资深开发,再到研究员兼技术经理。《资深开发讲技术》 从一线实战中总结有故事,有背景的案例,希望带给大家一系列技术盛宴。
项目背景:
java后端项目,线上Linux 环境,容器部署。
问题描述:
收到大量ERROR报警,用户反馈服务器响应部分接口变慢。
排查过程:
先看了下日志,一通排查后,发现一台容器日志各种异常,连接超时,zk超时,rmq超时等,其他台服务正常。这个很奇怪,怀疑是定时任务或者网络异常。
top命令执行后,容器的cpu负载很高。
看了代码发布记录,最近几天并没有发布新的代码。
此机器的定时任务并没有异常增多。
初步定为宿主机有问题。
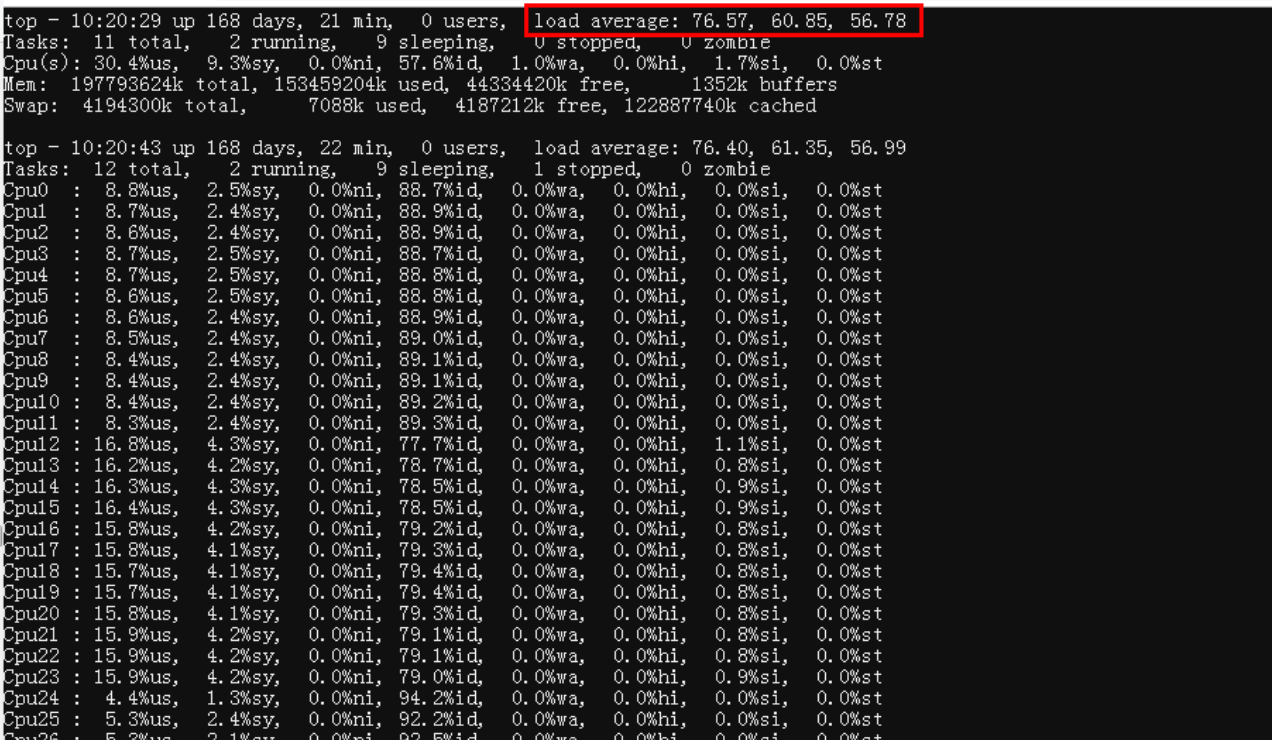
物理机top命令结果
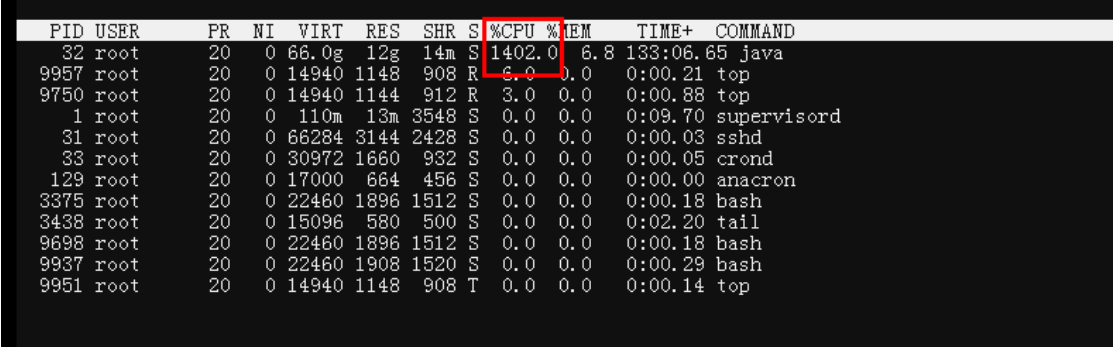
进程资源占用情况
解决办法:
记录宿主机地址,杀死容器,重新启动服务(目的是自动重新换一个物理机),线上服务恢复正常。服务正常后,和容器运维人员联合排查后,下掉了出问题的宿主机(已有多个团队投诉此物理机)。
分析过程:
很多资深的开发,可能会diss出现问题后,为什么要重启容器呢。做为一位对问题喜欢刨根问底的开发,我也很反感,出问题后先重启。
我赞赏的是,出问题后能够快速定位,如果不能快速定位,至少需要第一时间保留现场信息,然后快速恢复线上环境。毕竟第一时间,使线上环境恢复正常,是开发首要的任务。
对于本次故障,cpu负载很高。开发想打印现场信息,根本是办不到的。基本上服务已经不能响应指令了。
知识加油站:
1.CPU平均负载?
有时候我们会觉得系统响应很慢,但是又找不到原因,这时就要查看平均负载了,看它是否有大量的进程在排队等待。特定时间间隔内运行队列中的平均进程数可以反映系统的繁忙程度,所以我们通常会在自己的网站或系统变慢时第一时间查系统的负载,即CPU的平均负载。
2.top命令中显示的:load average: 0.15, 0.21, 0.34 什么含义?
负载后面的三个值表示:过去的1分钟、5分钟和15分钟内进程队列中的平均进程数量。
3.load average 多少的时候,表示服务压力大?
这个问题,看似很简单,但是很关键。以我多年的面试经验,多年开发经验的开发,懂的也并不多。负载大小和cpu的核数是有关系的。并不能一概而论,一般结论:CPU 负载小于等于cpu核数是安全的,比如是8核服务,那么cpu平均负载 小于等于8是正常的。
4.如果查看系统的逻辑核数呢?
请使用 lscpu指令截图如下:
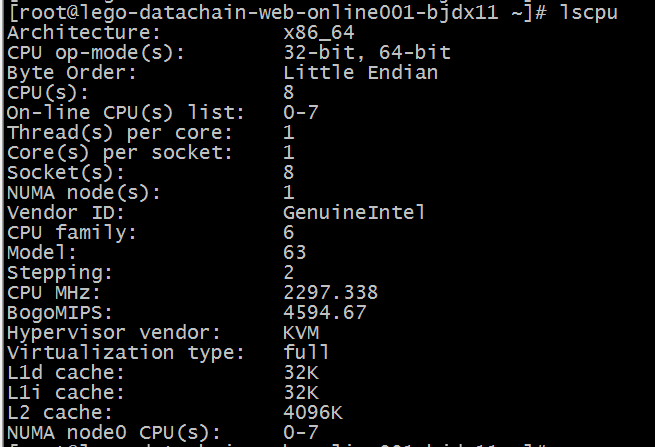
lscpu命令
5.cpu负载高的一般排查办法。
目前我的建议是直接使用阿里的 arthas。当然你也可以使用 top加jstack定位出问题的代码块。