内容简要
一、Vineyard的创建初衷
二、Vineyard的定义及功能
三、Vineyard和云原生结合
四、案例演示
五、Roadmap
一、Vineyard的创建初衷
(一)为什么需要一个分布式内存数据管理引擎?
首先,对于单机数据计算,PyData生态已经成为事实标准,这里数据在不同的Python库间0拷贝的共享非常的简单,因为数据都在一台机器的内存里,彼此间通过传递参数的引用就可以实现。

这里先是声明了一个numpy的array,然后另一个库pytorch可以从这个numpy array构造一个tensor,这个过程是0拷贝。可以看到,如果我们修改了tensor的值,array的值同样被修改了,因为它们指向同一个进程里的同一段内存。
那么,如果对于更复杂的计算场景,我们需要在不同的进程或者运行时之间0拷贝的共享数据呢?
一种方法是使用Apache Arrow的Plasma,它使用进程间内存映射来实现0拷贝,但这还是在单机环境下。
对于我们业务中常见的无法放在一台机器上的大数据,如果还要实现跨系统的0拷贝数据共享,应该如何解决呢?
Vineyard可以提供这种分布式环境下跨系统数据0拷贝共享的能力,进一步,如果和Kubernetes结合的话,还可以产生一种更灵活的计算范式,下面我将逐步展开。
(二)现实生活中的大数据应用

- 我们先看一个例子,如上所示,一个经典的反作弊工作流大致包含以下四个部分:
1) 购买记录的提取,这里会用到一些分布式的SQL引擎;
2) 从原始数据构造用户商品关系图,并通过标签传播等图算法计算节点风险,所以会引入图计算系统进行处理;
3) 用机器学习的方法,来提升风险检测的精度;
4) 对于得到的高风险用户和商品,进行在线人工处理,这里会用到一些数据可视化的系统。
可以看到,一个经典的大数据应用工作流中,往往会出现多种不同的计算需求,需要用到各种专业性的计算系统来逐一解决,而且往往都会使用一个分布式文件系统,例如HDFS,来解决跨系统数据共享的问题,这也导致每个子任务只有在前序子任务完全结束以后才能被启动。
这就带来如下三个问题:
1) 每个专业性的计算系统想要达到生产可用都非常困难,光是开发各种数据平台数据类型的I/O接口就要花费大量时间;
2) 使用文件系统交换数据带来大量的I/O以及序列化和反序列化开销;
3) 由于工作流被文件系统人为割裂,导致全局性优化方法无法实施。

以图计算为例,由于图计算的复杂性,针对各种场景下的具体问题,这些年从学界和工业界涌现了大量的针对性的图计算系统,但是它们却很少能达到生产可用。
这里面一个主要原因就是光是I/O,分布式部署,容错机制,系统扩展性,以及各类数据源数据格式的接入就需要花费大量的时间和人力。
(三)设计初衷
针对以上三个问题,我们研发Vineyard。
首先,Vineyard不仅为上层应用提供存储,同时采用可扩展设计,为上层系统提供I/O,分块,扩容和容错能力,从而减少上层系统在这些方面的开发工作;
其次,Vineyard采用基于共享内存的0拷贝数据共享,减少I/O和数据拷贝的开销;
最后,Vineyard提供系统间的Stream,提升工作流的整体并行效率。
二、Vineyard的定义及功能
(一)定义
首先,Vineyard管理的是分布式的内存中的不可变数据,也就是说,这些数据被存放在Vineyard以后,一经封存,就不再允许被更改。
这类数据在大数据应用中非常常见,一般来说,在一个大数据工作流中,上一个计算步骤结束后,它要传给下个步骤的数据就固定了,下一个计算系统对它的使用仅仅是读的操作。
其次,这类数据通过Vineyard传递给下一个步骤是0拷贝的,这是通过内存映射实现的。
同时,Vineyard还为这些数据提供开箱即用的高层次抽象,方便计算系统对这些数据的使用,例如Graph图、Tensor张量和DataFrame等等。
这使得上层系统可以像使用本地数据变量一样使用Vineyard上的分布式数据;
最后,Vineyard内建了大量的数据分块,读写,检查的驱动,同时采用可扩展设计,允许新的驱动以即插即用的形式在工作流中动态扩展Vineyard的功能,从而更好的支持上层工作流的开发和计算。
(二)系统架构
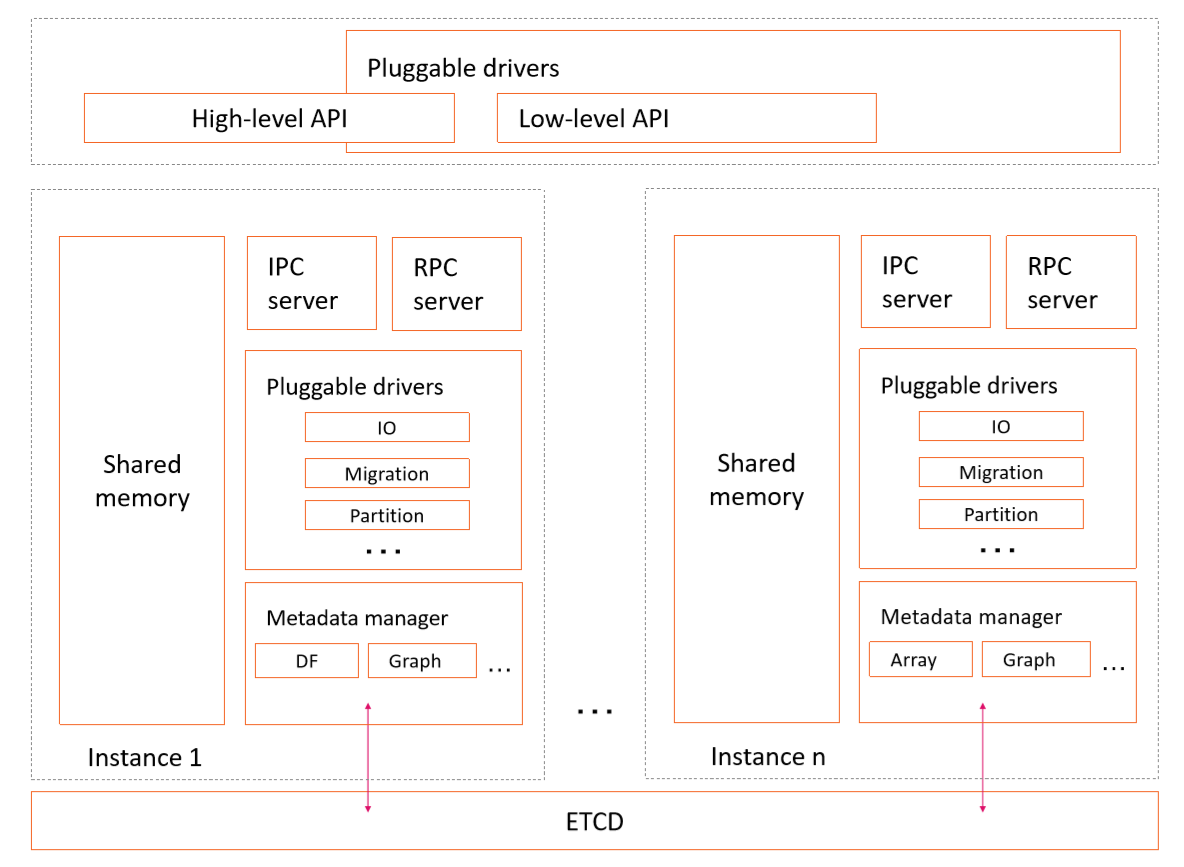
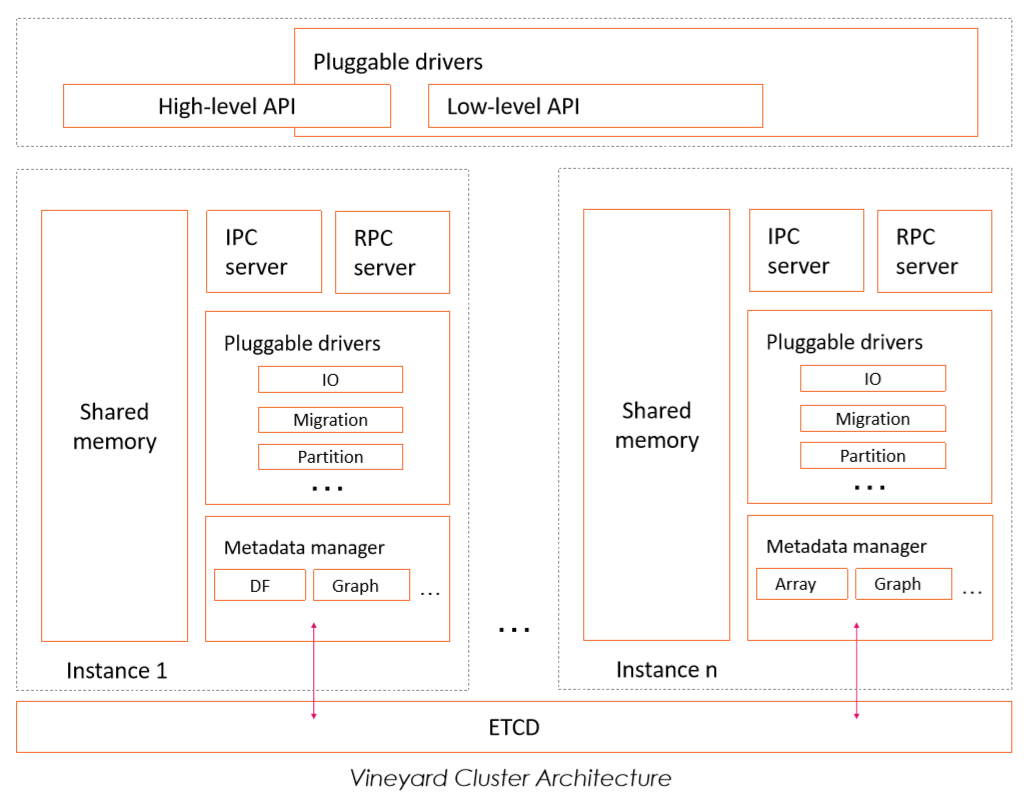
Vineyard系统架构图
具体来看,Vineyard的系统架构如上方所示。
首先,Vineyard里的每一个数据对象都包含数据负载和元数据两个部分,其中数据负载保存数据本身。
例如对于一个DataFrame而言,就是每一行每一列实际的值,而元数据包含DataFrame的shape、schema,以及DataFrame在分布式环境中是如何被切分和部署的信息等。这里元数据可以完备地解释数据负载,从而实现数据正确的复用。在Vineyard里,数据负载存储在共享内存中,而元数据通过后端的ETCD在集群上共享。
其次,Vineyard会在集群的每个节点上运行一个守护进程,负责这个节点上的数据负载。数据负载只能被IPC连接获取,并且通过共享内存实现0拷贝的数据共享,而元数据还可以通过RPC连接来获取。
这是因为对于一个经典的并行数据处理场景,我们可以先通过RPC连接访问元数据来获得数据在集群上的分布情况,然后再分布式的启动一系列工作进程,并通过IPC连接来真正获取数据负载并进行处理。
最后,Vineyard以驱动的形式,为其存储的数据对象提供各种内建的和即插即用的功能。
(三)案例说明
上图为一个分布式DataFrame的例子。
首先我们在第一台机器上,通过IPC域套接字连接到Vineyard,如下方所示:

然后我们通过对象ID获得这个分布式DataFrame,我们可以看到,它被分成多块,每个分块是一个单独的DataFrame;
在这里,这个大的分布式DataFrame是Vineyard的一个全局对象,而这个编号为0的分块是一个局部对象;
通常来说,一个Vineyard全局对象,由多个局部对象组成,并且这些局部对象分布在多台机器上。

这里我们可以看到,编号为0的分块存储在第一台机器上,相对于第一台机器,它是本地数据;
相反,编号为1的分块数据存储在第三台机器上,它不是第一台机器的本地数据。

我们继续获取编号为0的分块的数据负载,这里数据通过共享内存映射到当前进程,实现了数据0拷贝的共享。
而编号为1的分块不是本地数据,我们无法获取数据负载,但是可以获取它的元数据。
三、Vineyard和云原生结合
我们已经了解了Vineyard的基本概念,接下来我们来看Vineyard和云原生的结合的情况,以及我们打造的全新的计算范式。
我们会先介绍如何在Kubernetes上部署Vineyard,然后介绍Vineyard如何利用Kubernetes的能力,去实现数据和工作的共同调度,从而产生一种全新的大数据计算范式。
(一)Vision: 大数据任务的云原生范式

如上所示,还是之前的例子,在我们全新的计算范式下,它是这样被部署的:
首先,Vineyard以Daemonset的形式部署在Kubernetes上;
其次,每个步骤的计算系统也被迁移到Kubernetes上,这使得它们获得了动态扩展的能力;
最后,这些系统间以CRD,也就是Kubernetes上Vineyard自定义资源的形式,抽象中间数据。同时,Vineyard会利用Kubernetes的能力,协同部署中间数据和工作进程,确保每个工作进程都能获得它需要的数据,从而实现计算工作流的高效运行。
(二)在Kubernetes上部署Vineyard
目前Vineyard已经可以通过Helm来安装。
同时,Kubernetes上的数据共享是这样实现的:
首先,每个节点上的Vineyard服务Pod和其他工作Pod依然通过IPC连接来实现内存共享。
在Kubernetes环境中,域套接字可以通过被挂载到Pod中的hostPath或者PVC在不同Pod之间共享。
而对于Vineyard服务容器和工作容器被绑定在同一个Pod的情形,可以通过一个emptyDir类型的Volume在两个容器之间共享。
(三)Kubernetes的能力: CRDs
在使用Kubernetes的能力方面,首先Vineyard存储的对象会被抽象为Kubernetes的自定义资源,这个CRD中包含其对应对象的元数据。
同时,如果是局部对象,也就是比如刚刚说到的一个分布式DataFrame的某个分块,还会包含位置信息,也就是这个分块存储在哪个节点上。。
(四)Kubernetes的能力:协同调度数据和工作负载
由于局部对象的CRD中包含位置信息,我们可以利用它来协同调度数据和工作负载:
- 在工作负载Pod里描述这个工作需要的Vineyard对象的ID(通常是一个全局对象);
- 通过Kubernetes的scheluder-plugin来增强调度器的调度能力,使得当工作Pod被调度时,调度器会先通过CRD查看它需要的Vineyard对象所包含的局部对象的位置信息,从而优先将工作Pod调度到相应的节点上。
- 如果因为种种原因,无法调度成功,数据迁移则会被自动触发,从而保证工作Pod总是能够访问到它需要的数据。
四、案例演示
下面,我们通过一个Demo来展示Vineyard如何借助Scheduler Plugin实现数据和工作的协同调度。
这里使用一个简化版本来做Demo,我们会针对作弊交易数据构造一个作弊交易的分类器,在这个Demo里面我们会用Pandas和Mars分别在单机和分布式的情况下来预处理数据,同时用Pytorch训练一个作弊交易的分类器。
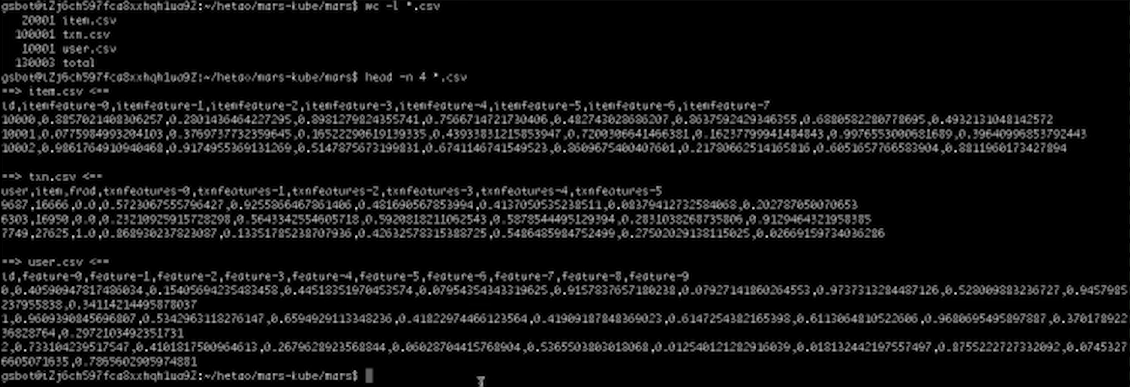
好,我们先来看看数据。如上所示,通常情况下Vineyard以及它上面的系统用到的数据都是非常大规模的数据,这里我们用一个小数据来做Demo,否则的话光是加载这个数据就要花费大量的时间。
这里有三张表,分别是用户表、商品表,还有交易表。用户表和商品表主要包含用户和商品的ID,以及它们各自Feature的向量。而这个交易表每一条记录表示一个用户购买一个商品,还有一个标签Frod来标识这条记录是否是一个作弊的交易,同时一些关于这些交易的Feature也都存在这个表里面。
对于这样一个问题,我们在单机的情况下是如何实现的呢?我们看一下 Pandas版本的代码,如下所示。

首先我们会加载数据,用Pandas读这三个文件得到三个DataFrame,然后把这三个DataFrame合并成一个大的Dataset,这里用到了DataFrame的Join,这是第一步。

第二步我们通过Dataset来训练模型,通过Dataset来构造Feature数据和Label数据。
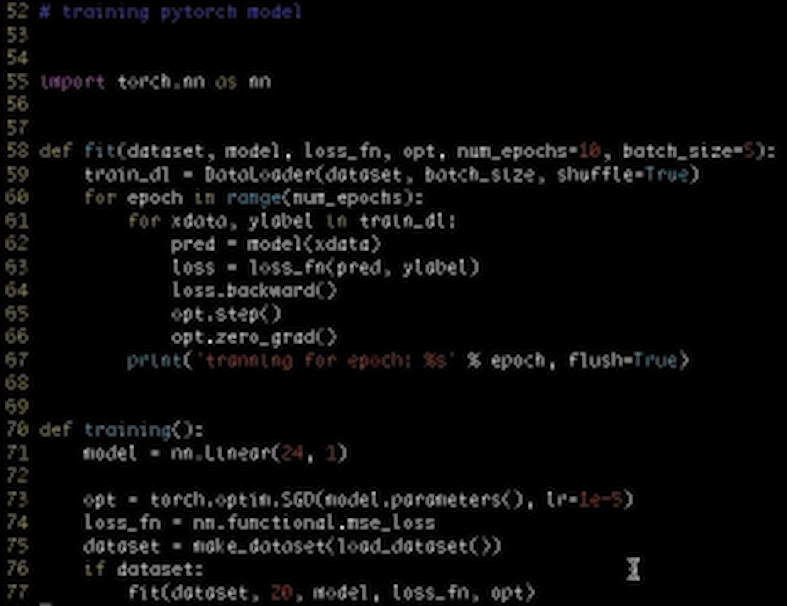
然后使用一个最简单的线性模型来训练分类器,这是单机版本的实现。
如果数据非常大,无法在一台机器上存储的话,那么这个单机版本的代码显然是无法实现这样的功能,因为Pandas甚至都无法去读这样的一个文件,这种情况下我们如何实现呢?
这里我们使用Mars来做第一步DataFrame处理的工作。
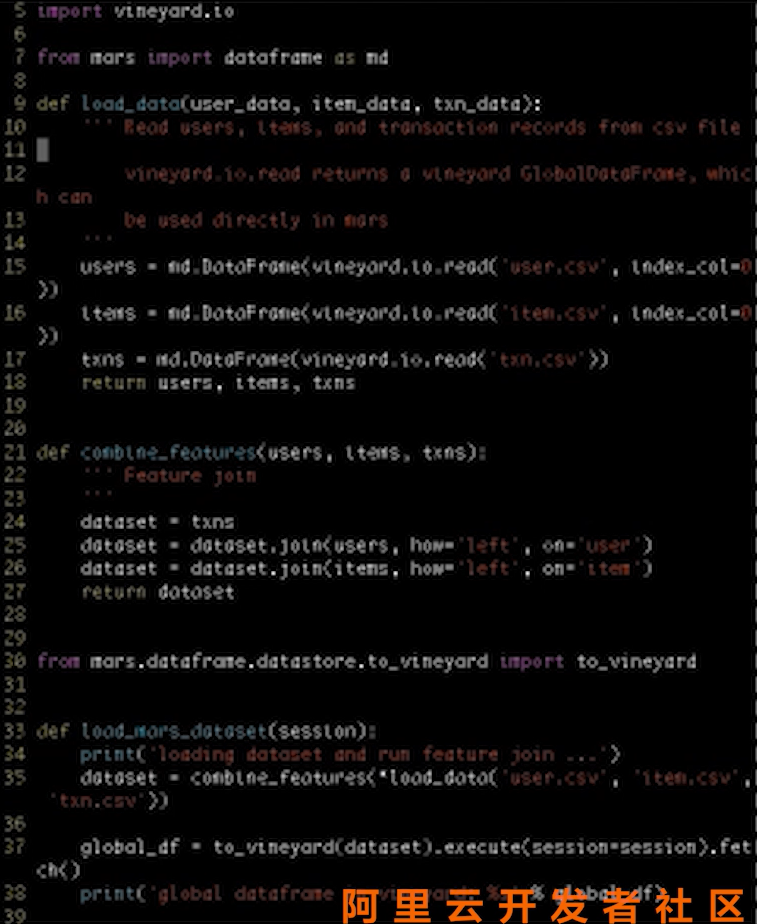
Mars是集团开源的一个项目,支持大规模DataFrame的计算。
对于一个Mars中的DataFrame分类,它和Vineyard类似,包含多个分块,并且分布在多台机器上,所以这里可以先用Vineyard将文件读成一个GlobalDataFrame,然后直接加载为Mars的一个DataFrame。
同时Mars支持DataFrame的计算,比如Join操作。Mars通过多台机器上多个分块间的并行计算,实现分布式DataFrame的交易操作。最后,Mars合并的大的DataFrame会以Global DataFrame的形式存进Vineyard。
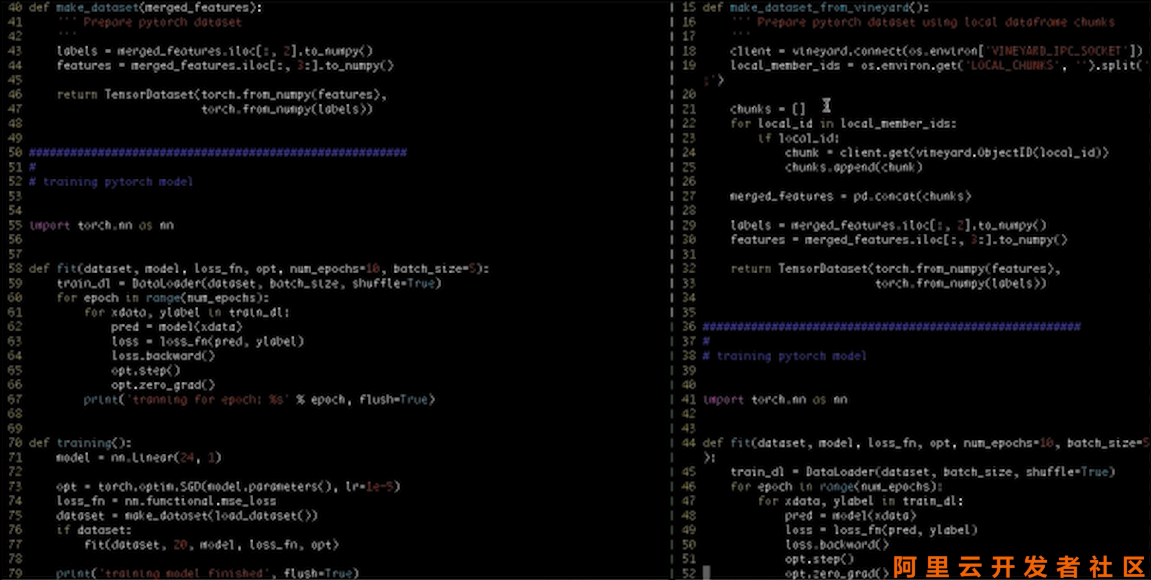
第二步使用Distributed Pytorch来进行计算。这里Distributed Pytorch要从Vineyard里Log出GlobalDataFrame,这个Distributed Pytorch会起多个工作进程,每个工作进程会得到相应的分块。
首先会建立一个Vineyard Client连接到VINEYARD_IPC_SOCKET,然后获得本地分块的ID,随后Client会拿到这些数据负载,并且把它们合并成一个总的表,并且通过总表和之前一样构建Pytorch Dataset,接下来训练的内容就和刚刚一致了。
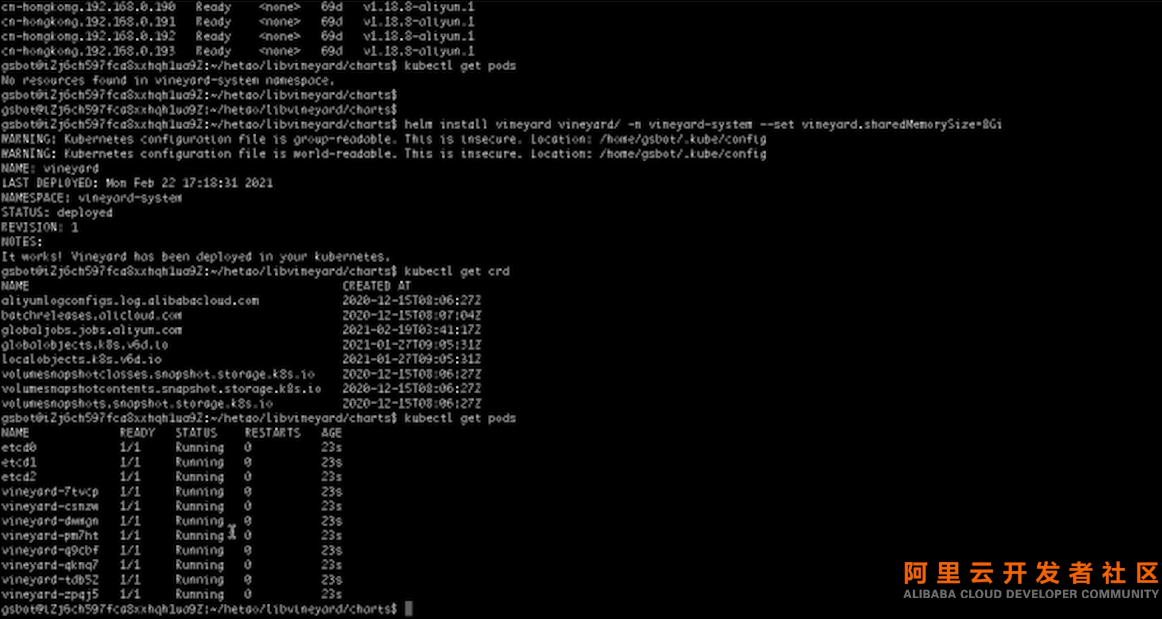
上图为实际执行Demo过程。
首先我们有一个干净的Kubernetes环境,接着用Helm安装Vineyard,安装了Vineyard以后得到了两个CRD,一个是全局对象,一个是本地对象。Vineyard在集群上运行是以Demon Set的形式,也就是说每个Log上都有一个Vineyard Pod。
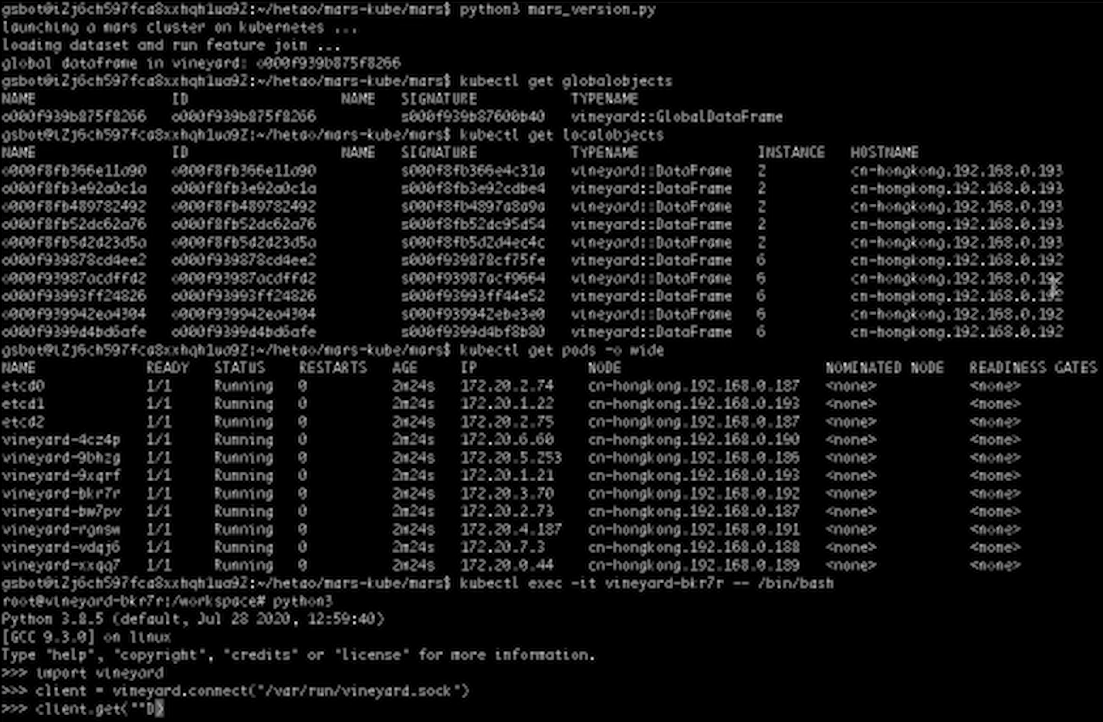
上图为Run Mars,Mars会启动一个集群,然后分布式地做这个计算,得到一个GlobalDataFrame与它的ID。
同样的,在Kubernetes里面有一个和GlobalDataFrame对应的全局对象,这个全局对象包含多个分块,也就是多个局部对象。可以看到全局对象分布在192和193两台机器上,可以登录192查看其中一个分块具体长什么样。
通过Import Vineyard然后建立一个IPC Socket Client,然后选取一个192上面的一个分块来Get。

可以看到我们得到了DataFrame,它是我们刚刚大的DataFrame的一个分块。

我们再试图get一下193上面的分块,可以看到我们无法拿到这个分块,所以如果我们的工作Pod在被调度的时候,没有和数据所在的节点对齐,就会发生无法获取数据的问题。应该如何解决呢?我们看一下Pytorch的Yaml。
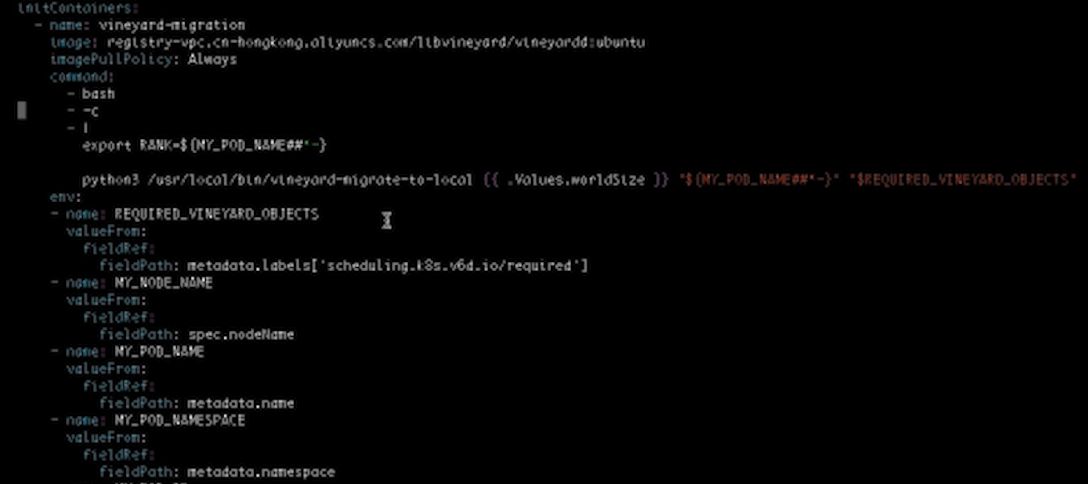
在InitContainers里面我们增加了一些内容,它可以确保当数据和工作负载没有被对齐的时候,数据迁移会自动地被触发,下面我们来Run Pytorch。
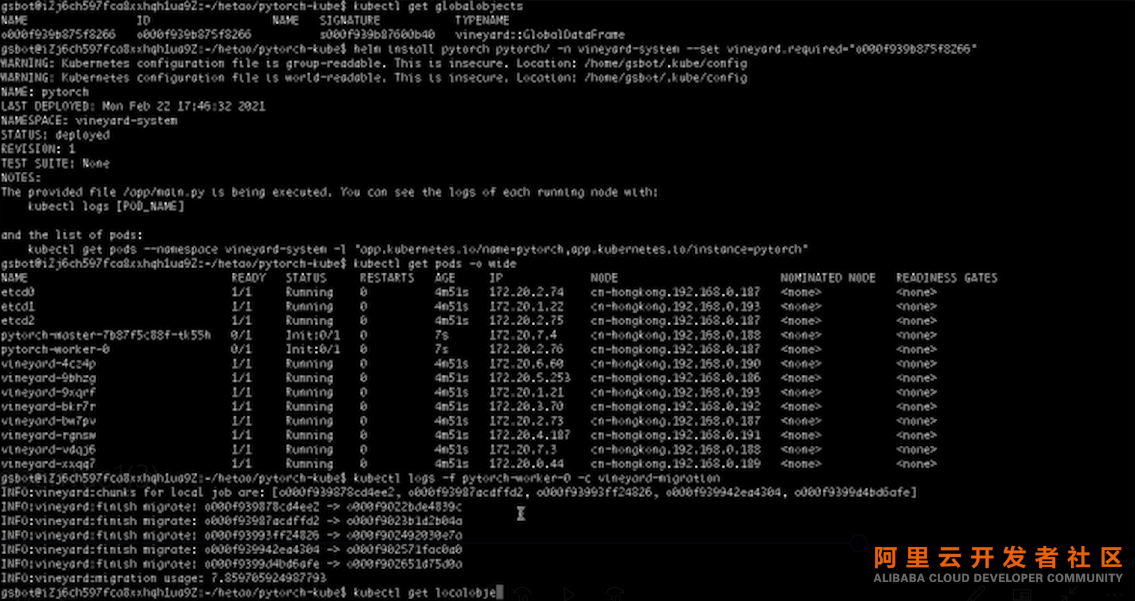
首先查看全局对象并拿到 ID,然后把ID输入给要Run 的Pytorch。
Pytorch部署到Kubernetes后,可以看到其中两个Pod运行在188和187上,和刚刚的192、193没有对齐,那么这里会发生什么呢?我们看一下worker-0的Log,可以看到数据被自动地迁移了,但是数据迁移的过程是很花费时间的。
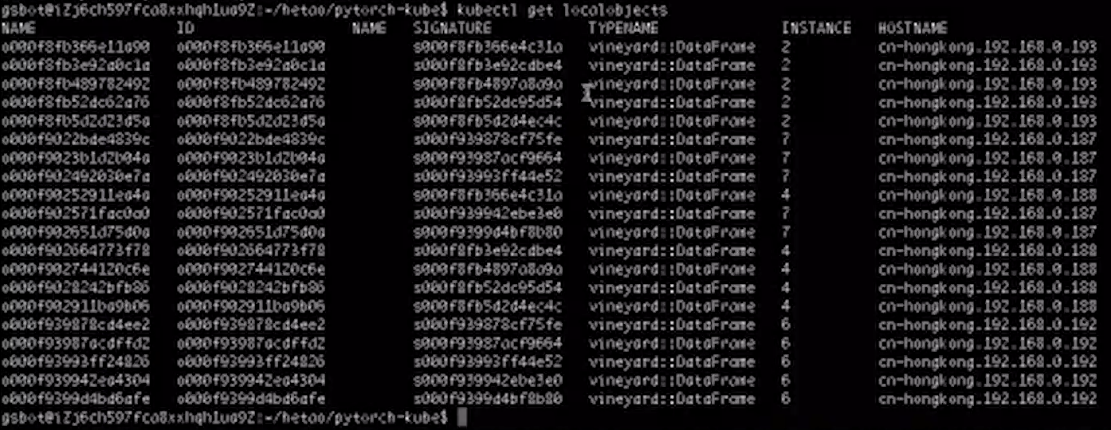
这里由于数据迁移,我们会产生重复的局部对象,比如31a也被复制了,它从193被复制到了188,从而我们的Worker可以使用它。
可以看到,数据迁移的过程不仅会花费时间,而且还会浪费内存,所以我们应该想办法去尽量减少这种数据迁移的发生,这也就是为什么我们要用Scheduler Plugin来增强Kubernetes的调度能力,从而减少这种数据迁移的发生。
下面把环境清理一下,重新Run以上过程,不过这一次会使用Scheduler Plugin。
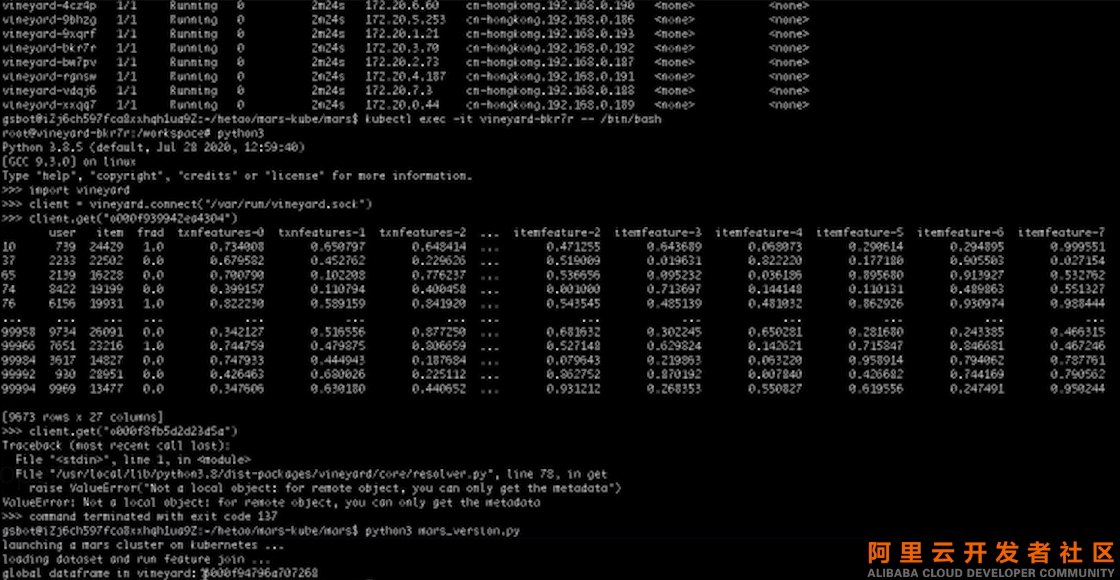
重新安装Vineyard,重新再执行一遍Mars,又得到了一个GlobalDataFrame,那么我们接下来检查一下,全局对象所包含的局部对象在我们集群中的位置。
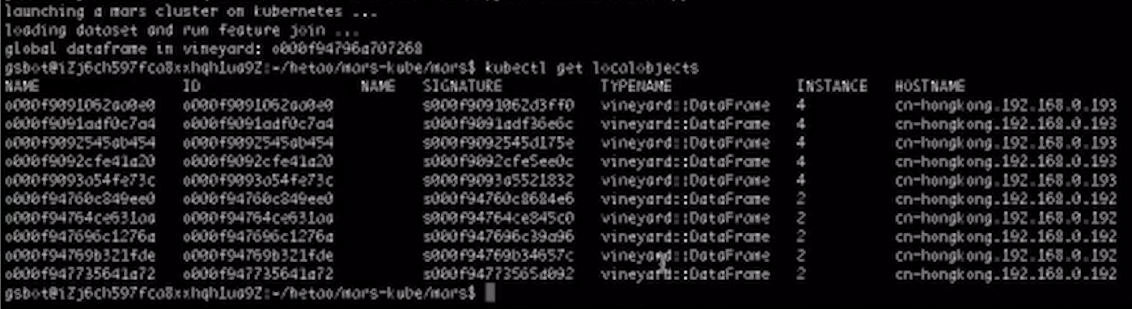
可以看到,它依然是在192和193这两台机器上,接下来要安装Scheduler Plugin。
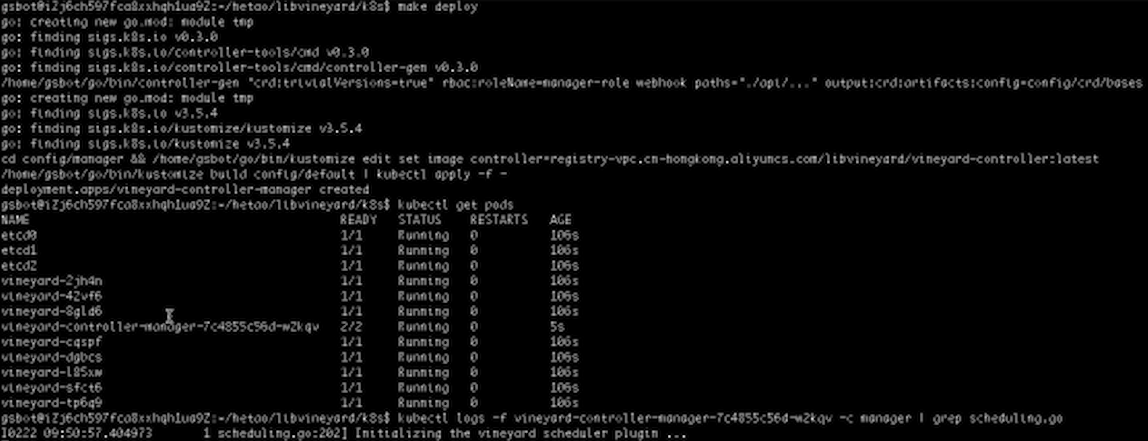
Scheduler Plugin会根据工作负载所需要的Vineyard对象的位置来调度这个工作的Pod。后面会通过观察Scheduler Plugin的Log来查看这个过程。

再次打开Pytorch的Yaml,可以看到我们把需要的Vineyard对象的ID写在了这里,Scheduler Plugin可以通过读取这个Spec来知道工作负载是需要哪一个Vineyard对象。
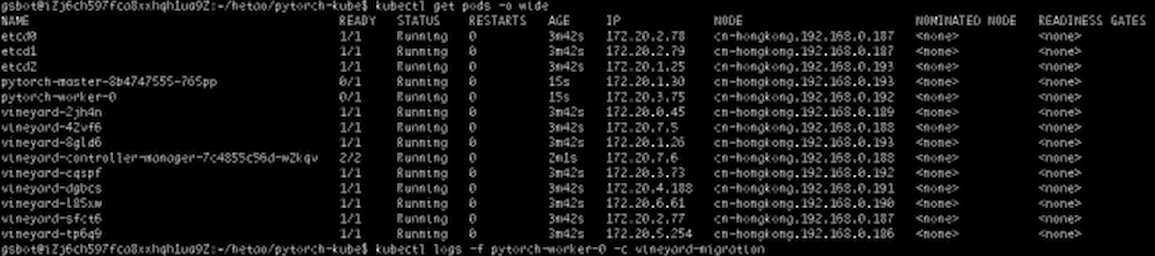
我们运行Pytorch拿到 ID,Set Scheduler Plugin,可以看到两个Pod已经运行在192和193上面,接着我们去看一下Scheduler Plugin的Log,可以看到Scheduler Plugin给193和192两台机器打了最高分。回到Worker-0的Log,可以看到没有数据迁移发生,也没有重复的局部对象被创建,是因为没有进行任何的数据迁移。
在这里我们通过Scheduler Plugin成功地将数据和工作负载对齐,进行协同地调度,从而实现了高效的并行计算。
以上是Vineyard利用Scheduler Plugin实现协同调度的Demo,这为我们打造基于Vineyard和Kubernetes的高效且灵活的大数据计算范式,打开了一扇大门。
五、Roadmap
(一)项目状态
目前,Vineyard在GitHub已经收获375颗星,同时有6位同事在维护这个项目,我们期待获得来自社区的更多的支持,也希望有社区成员可以逐步成为Vineyard的维护者。
(二)Roadmap
- 当前:
1) 通过Github Actions构建和测试;
2) 支持各种数据类型,如数组、图形,并支持多种计算引擎,如pytorch, mars, GraphScope;
3) 在DockerHub和Quay上释放;
4) 与Helm进行集成。
- 未来:
1) Vineyard Operator for Kubernetes;
2) 性能改进;
3) 更多语言SDK,如Java, Go等;
4) 存储层次结构;
5) Scheduler-plugin:Fluid
在未来的规划中,我们首先会在Kubernetes上做功能性更强的Vineyard Operator,比如检查点,容错等。此外,我们还会和集团的Fluid合作,进一步优化调度能力。